
Hey everyone! It’s been a minute since my last post. Work has been absolutely crazy lately had a few tight deadlines that ate up all my free time. But I finally came up for air, and I wanted to document something I’ve been wrapping my head around recently.
As an ai engineer, I thought I had CI/CD figured out. You write code, tests run, build passes, you deploy. Simple.
But recently I started digging into AI Engineering, specifically how to productionize models without losing my mind. I quickly realized that treating an ML project like a standard web app is a recipe for disaster. The « aha moment » for me was understanding that in MLOps, the training pipeline itself is the product.
I found a really good architecture diagram recently that visualized this perfectly. I’ve redrawn it below to highlight the key parts. Here is my take on how to actually structure this without overcomplicating it.
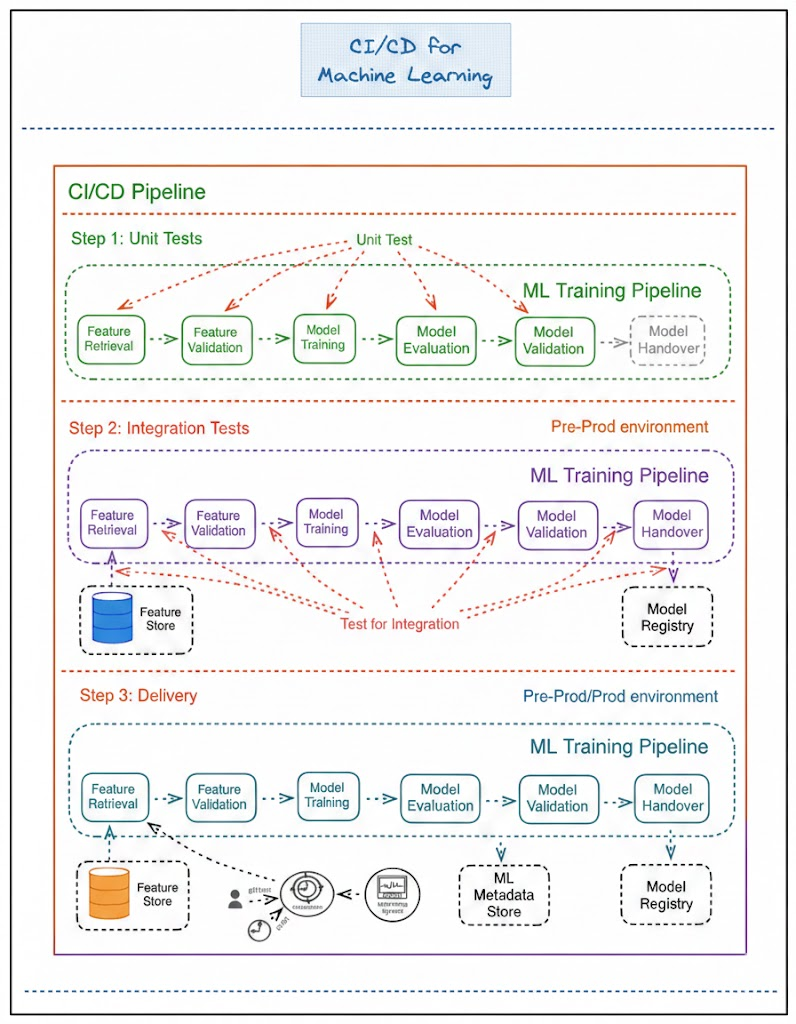
The Mental Shift
In traditional software, your pipeline delivers an executable (like a .jar or a docker container). In ML, your pipeline delivers… another pipeline.
You aren’t just shipping the model; you are shipping the factory that makes the model. If you don’t treat that training pipeline as a « first-class citizen, » your project will likely fail when it hits production.
Let’s break down the three layers of testing and delivery that make this work.
1. Unit Tests (The « Sanity Check »)
This part feels familiar. Just like in regular dev work, you need to verify your logic.
In a mature setup, your ML pipeline is broken down into modular steps (Data Retrieval, Validation, Training, Evaluation). The goal here is strict isolation. You aren’t testing if the model is « smart » yet; you’re testing if the code is broken.
- Does the data cleaning function actually handle nulls?
- Does the training script crash if I feed it a specific input?
Basically: does the code do what I told it to do? If this fails, there is no point in moving forward.
2. Integration Tests (The Ecosystem)
This is where it gets tricky and where MLOps differs from DevOps.
An ML model doesn’t live in a vacuum. It has to talk to a weird ecosystem of tools. In this stage (usually in a pre-prod environment), we test the connections.
- The Feature Store: Can the pipeline actually connect and pull the raw data?
- The Hand-off: Does the « Training » step successfully pass the artifact to the « Evaluation » step?
- The Model Registry: Once the model is trained, can the system successfully register it and log the metadata?
If you skip this, you might have a perfect model that you can’t actually save or deploy.
3. Delivery (Continuous Training)
This is the end goal. In standard software, « Delivery » means the user can log in. In ML, Delivery means the pipeline is live in Production and ready to react.
The keyword here is Continuous Training.
Once deployed, your pipeline is sitting there, waiting for a trigger. Maybe it’s a cron job (retrain every Sunday at 2 AM). Or, more impressively, it’s triggered by Concept Drift. If your monitoring system notices the live data is changing and the model is slipping, it can automatically kick off the pipeline to retrain itself.
Final Thoughts
Honest opinion? This stuff is harder than it looks. It requires shifting your mindset from managing code to managing Code + Data + Models. But once you set up these three layers Unit, Integration, and Delivery you stop worrying about breaking production every time you tweak a hyperparameter.
I’m still experimenting with different tools for the « Orchestrator » part (Step 3). If you guys are using Kubeflow or Airflow for this, let me know in the comments. I’m curious to see what the standard stack looks like for you.
