
Summary
Hello everyone ! 👋 This is Kbilel and welcome to our second article on LLM .
In the previous blog, we discussed what LLM (Large Language Model) is and provided an example to illustrate its usage. 🧠💻 As a post-training topic, we briefly looked at how to evaluate the performance of machine learning models. 📊✅
Starting today, we will gradually dive deeper into the content covered in LLM. First, let’s begin with an introduction to natural language processing (NLP), a field where computers are taught to understand and interact with languages used by humans (such as Japanese 🇯🇵 and English 🇺🇸).
Stay tuned as we explore this exciting field! 🚀
What is natural language processing?
Natural language refers to languages that humans use in conversation, such as French, Japanese and English… The field in which computers process and handle these languages is called natural language processing.
In natural language processing, there are many different tasks (specific topics you want to solve). Let’s list them below:
- Morphological analysis
- After breaking down a sentence into words, check the part of speech and conjugation of each word.
- Named Entity Recognition
- Recognizes expressions such as names of people and famous people, names of organizations and famous people, dates, and amounts of money from text
- Sentence similarity judgment
- Determine whether the contents of sentence A and sentence B are similar
- Text Classification
- It categorizes sentences into categories, for example, into categories of negative and positive sentences.
- Text Generation
- Outputs words that follow a given sentence, or outputs sentences that meet a given condition
The above is just one example, but even if the same human sentences are used as input, the output exists for a variety of purposes.
What computers do to understand language
When solving natural language processing with a machine learning model, the input during the learning and inference steps of the machine learning model is text.
However, as we know with loss functions, the input needs to be converted into a number before the computer can receive it.
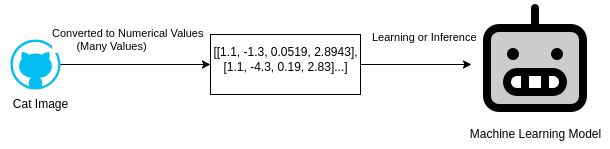
A distributed representation is a conversion of a sentence or word into a collection of numbers, which is called a vector in mathematics . We will discuss how to convert a sentence into a distributed representation from next days onwards, but for now, all you need to know is that « even if it is a sentence, if it is converted into a collection of numbers (vector), a computer can understand it! »
Among the machine learning models that take text as input, those that use neural networks are called neural language models . We plan to introduce neural language models in a future post.
What is the benefit of using distributed representations of text?
I mentioned that the results of a numerical conversion called a distributed representation can be processed by a computer. I also mentioned that this distributed representation is a vector, and the fact that it is a vector is an important point.
By the way, do you know what a vector is? For those who don’t know or have forgotten, it is something that represents distance and direction using numbers.
For example, in Python, a vector is represented as follows:
[1.1, -1.3, 0.0519, 2.8943]
By learning vectors like those above, which show distance and direction, it is possible to determine sentence similarity, classify sentences, and generate sentences.
We plan to introduce examples of sentence similarity, sentence classification, and sentence generation using simple Python code next days in the advent calendar (stay tuned ).
A non-machine learning method for visualizing text as input
In this advent calendar, we have touched on machine learning and have not introduced anything other than machine learning, but since we are talking about natural language processing, I would like to introduce some examples other than machine learning that can be easily verified with Python code.
It’s called a word cloud. It’s a way to visualize text, and it looks interesting, so please try it out if you like. Let’s check it out with the smallest possible code.
First, install the necessary items to display in French.
# Installing Japanese font as it is not available
sudo apt-get -y install fonts-ipafont-gothic
# Then I run some Python code to generate a word cloud, which is a visual representation of which words are most commonly used across a set of texts.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
input_text_data = """
This is a simple sample code for creating a word cloud.
Visualizing text with Python makes it look interesting.
Although it is not a machine learning method, the field called natural language processing has various other interesting contents.
If you are interested in word clouds, it might be good to look into morphological analysis tools called MeCab or Sudachi next.
"""
# Generate the word cloud
wordcloud = WordCloud(width=800, height=400, background_color="white", font_path='/usr/share/fonts/opentype/ipafont-gothic/ipagp.ttf').generate(input_text_data)
# Drawing settings
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
# Display the word cloud
plt.show()

If you are interested in word clouds, try searching for the keyword « morphological analysis. » You will be able to see how to divide a sentence into units called morphemes.
Conclusion
Today, I have briefly talked about natural language processing. In natural language processing, the input is text, but what the machine learning model can learn from the text varies widely.
The thing I want you to remember most about today’s blog is about distributed representations. I think it will come up frequently in future blogs.
Regarding the word cloud introduced today, I mentioned the keyword « morphological analysis » as the next thing to look up. In fact, next days I will introduce something similar to the tokenizer.
That’s all for today. Please check out next days blog!
